引擎暂时只是v8, JavaScriptCore、SpiderMonkey、Chakra、Carakan等等这些回头再看看做做对比啥的吧……
其他语言是以C/C++为例。
测试环境为Mac,并列出浏览器 or 环境的版本
- Chrome: 56.0.2924.87 (64-bit)
- Firefox: 51.0.1 (64 位)
- Safari: 10.0.3 (12602.4.8)
- Node.js: v7.7.2
持续更新中… 只是个持续更新的笔记而已,只是希望能说明白罢了!!
前言
C的访问机制,基本是编译确定了位置,偏移信息共享,使用时直接使用偏移量,所以非常高效。而js则不然,它在执行阶段才能确定结构,而且还能够增减对象的属性,在查找值时需要匹配属性名才能找到正确的值,这是很浪费时间的。
不过引擎们做了很多努力,已经在逐步接近其他语言的性能了,例如隐藏类。
这里说到的东西目的主要是为了避免让引擎的优化被浪费,甚至是倒退。
其实呢,对于WebGL这类的貌似更有用一些,对于一般开发倒是意义不大。
数据类型
在v8中,除了基础类型 Boolean、Number、String、Null和Undefined以外,其他都是对象。
在v8中,数据以两种形式来表示:
- 值:例如 String、对象等,它们是变长的,而且内容的类型也不一样。
- 句柄:大小是固定的,句柄中包含了指向数据的指针
v8实际上将所有的数据交由GC管理的,被定义在内部,我们不能直接操作,只能通过Handle(句柄类)来进行操作,所以访问的时候都是先找到Handle,再通过指针去访问实际的值,修改的时候也是修改Handle中的指针。
除了极少数的数据例如整型,其他的内容都是从堆里申请内存来存储的。
Handle本身能够存放特定数据,这也就使得这些数据不需要再从堆中分配,这也就减少了内存的使用并增加了访问速度。
在v8中,Handle对象的大小是4/8字节(32/64位机器),在JavaScriptCore中是8字节。JavaScript的数字尽管按照标准都应是64位浮点格式来表示,但是对于整数实际的操作是基于32位整数,这也就意味着可以在Handle中直接存储整数以达到快速访问的目的。
但针对着32位的Handle对象而言,它至少要区分存储的数据是整数还是指针,而指针本身的最后两位都是00,其实是不需要的,所以,就用这两位来表示句柄中包含的数据的类型,最后一位如果为0表示是整数,如果是1则表示是其他类型。
所以v8中实际能够直接快速使用的整数是小整数,31位的有符号整数。
v8中的Handle数据表示: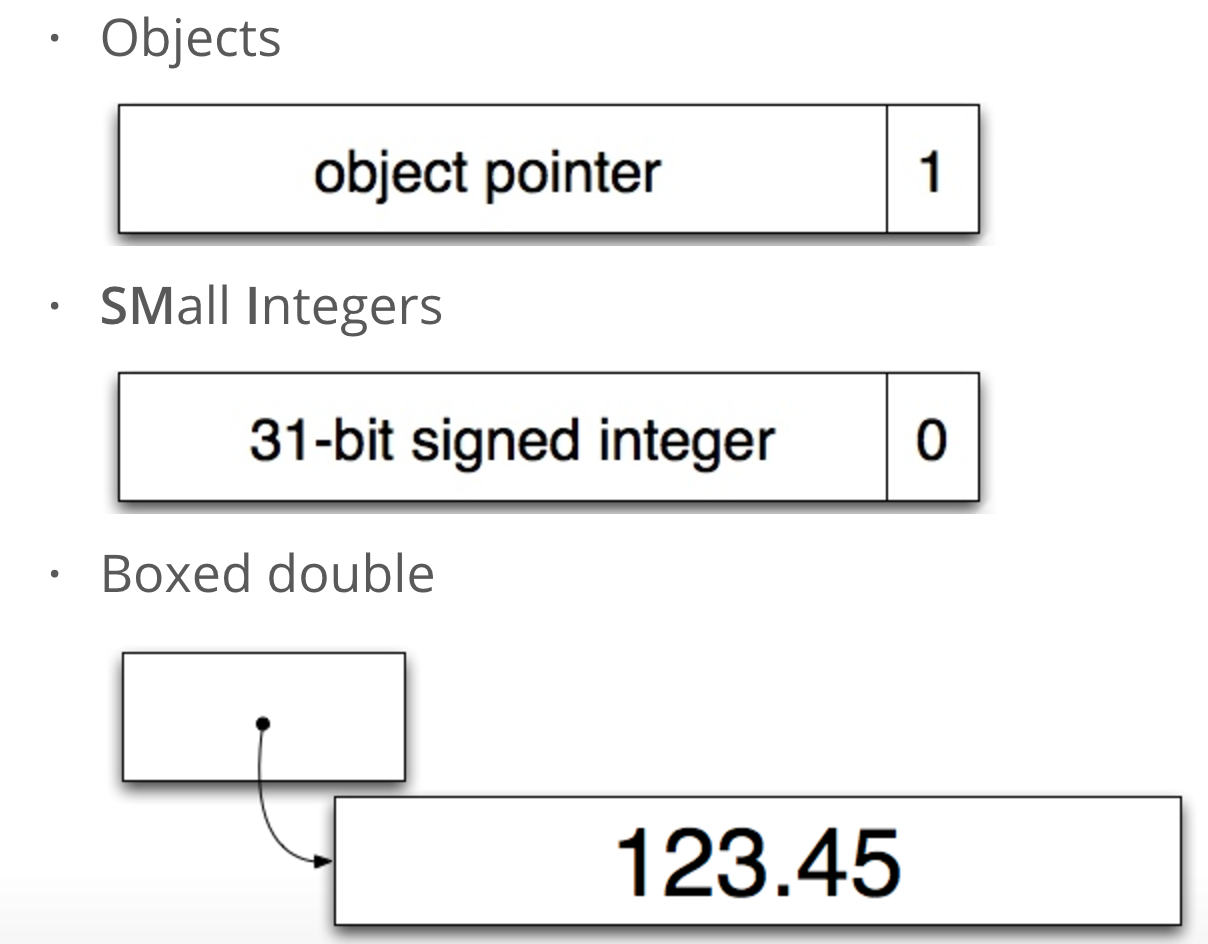
超过31位的数字,则被转换为double,放到一个Object中,再用指针指过去。
开发指引
- 尽可能的使用31位有符号的整数,它很快![-1073741825, 1073741824]
数组
我们都知道数组这种数据结构,它的经典实现就是:内存中一段连续的位置分配来存储数据的线性集合。在其他语言中,它是需要在声明时固定类型、指定长度,以便在栈区分配内存,并且长度是不可变的。
数组能够高效的访问,其实就在于内存的“固定”分配机制,元素类型固定,每次偏移的长度也是固定的,那么对于访问而言,仅需要计算地址位移信息而已,仅需要几个机器语言指令就可以存、取及使用。
js的数组本质是个对象,但在v8中,以非负整数为key的元素被称为Element,每个对象都有一个指向Element数组的指针,其存放和其他属性是分开的,这其实也是针对数组的优化。
那么Element,其实也就是数组元素,它有两种类型:
- Fast Elements: C语言模式的数组内存分配
- Dictionary Elements:hash table
毫无疑问,Dictionary Elements要比Fast Elements慢很多,所以从性能角度而言,我们要做的事情是避免Dictionary Elements的出现。
什么状况下会导致Dictionary Elements的出现呢?
- 过大的预分配数组,通常阈值是 64K(PagesPerChunk的大小限制?)
- 在非预分配的数组中,过多的超越当前数组长度的下标赋值,这个阈值由kMaxGap决定,通常是1024
- 删除元素也有可能会导致
至于过多的“洞”出现在数组中会不会导致转换为Dictionary Elements暂时还没有明确的结论,不过不建议这样的用法。
示例:
再来看Fast Elements,它其实也有三种类型:
- Fast integer values
- Fast doubles
- Fast values
这里其实是由元素类型导致的不同类型,所以可以再看一下上面的数据类型这部分
首先是整型,v8为了提高效率,31位有符号整数是由Handle保存的,所以处理起来是极快的。
再来是 doubles,常见的触发条件就是在整数数组中增加了一个浮点数,这会导致整个数组都被展开转换为double来存储,通过增加一个隐藏类实现的
最后是 values,例如再加入了一个true|undefined|null,这时候就要再次增加隐藏类,指明要存储的是Object
如果涉及到了这些转化,都会是性能的消耗,所以我们要尽可能的避免这种情况的出现。
然而如果一开始就初始化如:let arr = [1, 2, 1.5, true],并没有这样的转换问题,所以复杂类型的字面直接初始化是一个好主意,但是更好的主意是:尽量的在数组中存储相同类型的元素。
在Google IO 2012年的v8讲解中有这方面的讲解,清晰易懂,建议查看一下:视频 PPT
上面的说到的东西谈及了一个概念:隐藏类,这个会在后面的部分再细说,在这里只需要知道这个就行了:数组的Fast Elements模式默认是小整数,随着不同类型值的进入,会导致数组类型发生转换,都是通过隐藏类来实现的,而这个转换往往是一种不必要的消耗。
下面的代码注释部分就是在说明隐藏类
|
|
可以看出,有洞、无洞也会是隐藏类的一个标记,所以洞的出现不可避免的会造成性能的下降。
实验
测试预分配与动态分配
|
|
计算10次运行的平均值,结果依次为 a 和 b,Safari不支持performance.mark,所以都用了new Date()计算:
1000W次运算的结果
- Chrome: 295.8, 72.3
- Node.js: 290.4, 65.7 (它也是v8)
- Firefox: 77.1, 73.1
- Safari: 53.2, 13.4
100W:
- Chrome: 24.8, 4.9
- Node.js: 24.1, 5.5 (它也是v8)
- Firefox: 6.4, 5.9
- Safari: 5.7, 1.5
10W及以下几可无视差别。
其实还尝试了小额内存预分配(<64K)且试探性的内存延展(1024),不过从实验结果上来看由于引入了额外的计算,反而时间较内存自动分配有所增加。
逆向赋值的测试
|
|
测试结果几近相同,b的表现偶尔会变坏一点点,但是不知是不是触发什么bug了,Firefox直接在逆向赋值崩掉了,刷出了61.3, 5782这样令人崩溃的结果。
anyway,不要逆向赋值了!!
开发指引
- 使用非负整数作为数组下标,不要使用负数、浮点数、字符串等会被认为是一般性的Object的key
- 在数组中存储同一类型的元素
- 尽量的避免使用不连续的索引值,而且从0开始
- 如果非要存不同类型的元素,那么使用字面直接量初始化而不是一个一个的存入
- 预先分配数组大小,这在大多数状况下都有较大的性能提升,可以忽略掉64K的限制,但是小于万量级的话差别几可无视
- 不要逆向赋值!!不要逆向赋值!!不要逆向赋值!!
- 最好不要随便删除数组元素,这可能会导致转为
Dictionary Elements,据说洞变少可能会被v8优化回紧凑结构,但是这是不可依赖的行为 - 先赋值,再访问,避免使用
arr[100] == null或者隐式转换的判断性访问。
对象(隐藏类)
之前说过,js中除了那五种基础类型,其他的都是对象。而js又是个弱类型的语言,为了能够达到优化的目的(还记得与C类语言的特点么?就在前言部分。),即提升读取性能,v8利用动态创建隐藏内部类的方式动态地将属性的内存地址记录在对象内,从而提升整体的属性访问速度。
避免了通过字符串匹配的方式来查找属性值。
隐藏类是为Object服务的,相同结构的Object会共享隐藏类,当结构发生了改变,对应的隐藏类也会发生改变,要么复用,要么新增。
而且会将使用过的隐藏类结构通过内嵌缓存(inline cache)缓存起来,以便复用时可以快速的访问偏移值。
复用的一个最佳例子就是类的使用了:
|
|
需要注意的是,隐藏类将属性这些东西解析为树,所以顺序不同的初始化会导致隐藏类的解析结果也不同。
所有的Object类型都是这样。
开发指引
- 一次性的初始化所有的属性,而不是后续的动态增加
- 属性初始化的顺序应当一致,以便保证能够复用隐藏类。
delete会触发隐藏类的改变,如果是为了内存回收,设置为null是更好的选择
函数
避免触发优化回滚
v8有一个优化行为,针对于热点函数,会使用Crankshaft编译器去乐观且猜测性的生成高效的本地代码,这通常是建立在变量类型不改变的前提下,如果发现类型变化了,那么v8就会使用优化回滚(Deoptimization)机制来回滚到之前的一个没有经过特别优化的代码。
例如:
或许目的只是为了等一段时间之后打印当前时间,但是对于v8来说,waitThenGo执行了很多次之后,就可能会触发Crankshaft编译器来生成优化的代码了,它认为已经知道了所有的信息了,例如类型。
但是实际上,没运行到 now 这一行之前,我们都不知道 now 的类型,所以当运行到这一行时,v8就别无选择的只能回滚到一个通用的状态了。
开发指引
- 随用随声明是好的,但是如果前面的代码会触发大量的执行return,那么提前声明后面的变量是能够在一定程度上起到优化效果的